The search that already had my answer
Fantasy Joes is a fantasy-football game built on one move: I show you two NFL players, you tap the one you’d rather have. Do that enough times and the game learns your rankings without you ever typing a list.
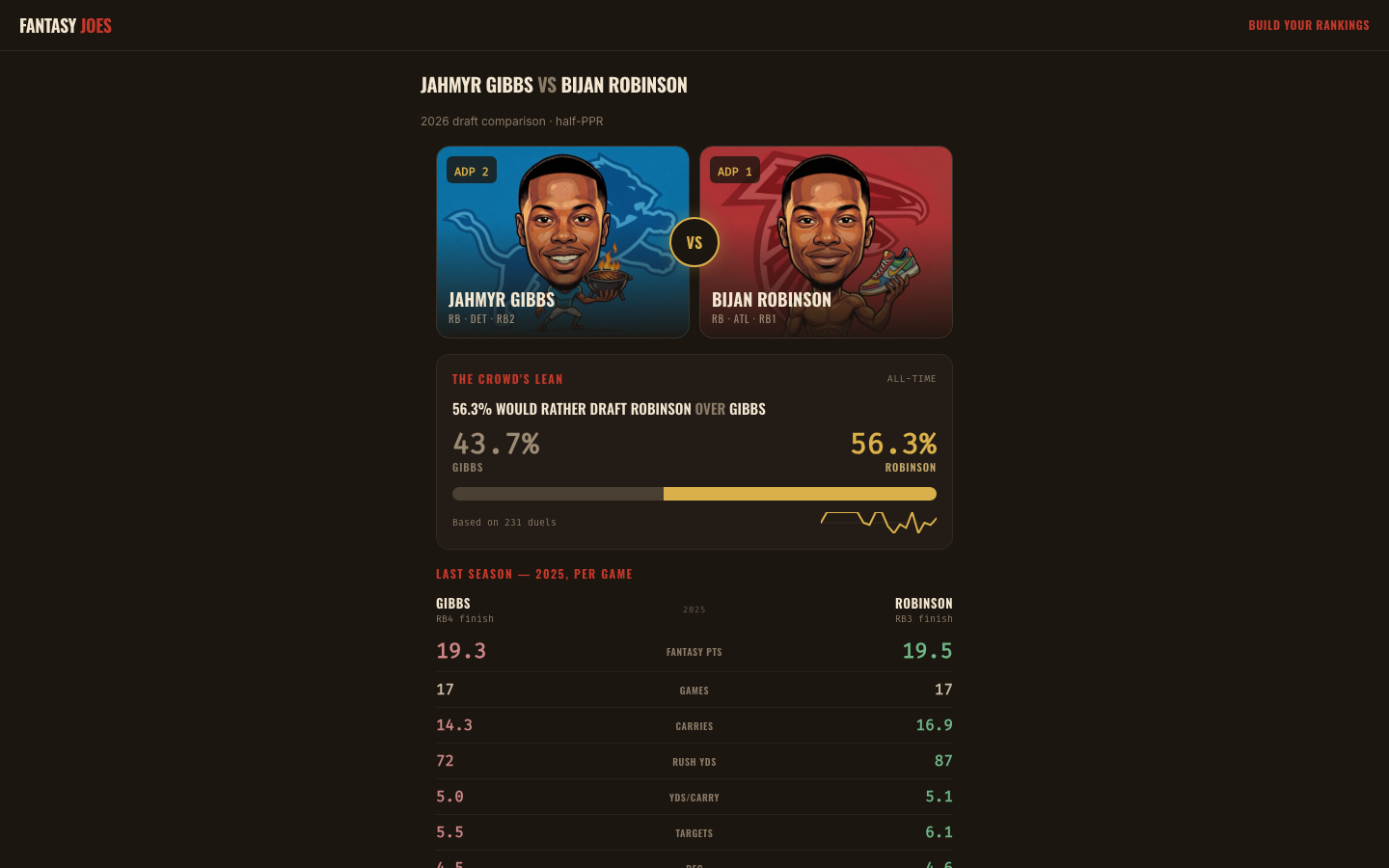
A side effect of that mechanic is that the game knows how a lot of people would answer any given matchup. For any two players it has enough picks on, it can tell you which way the crowd leaned and by how much — a 60/40, a 70/30, whatever the picks actually came out to. That number is a straight count of real choices, not an estimate of what people probably think.
Then it occurred to me that “player X or player Y” is one of the most common things people type into Google before a draft. They’re on the clock, or building a cheat sheet, and they want a second opinion on a close call. My game produces exactly that opinion as a byproduct. So I built a page for every close call the game had enough data to answer.
There are 145 of them live as I write this, in early July 2026. Two you can look at:
How a page gets built
I didn’t write any of these pages by hand, and there’s no list of matchups I picked. A job runs once a day, reads every draft-mode duel that’s been resolved, and groups the picks by pair of players. For each pair it works out the all-time split, the split over the last seven days, and which way the trend has moved over thirty. That’s the page: the crowd’s actual verdict on this exact matchup, plus how fresh it is.
A pair only gets published once it clears a bar — at least 25 total picks and at least 10 different people. Below that, the split is just noise, so the page doesn’t exist. If a matchup that was popular goes quiet and drops back under the bar, the page unpublishes itself and falls out of the sitemap. I never touch a list; the data decides what’s a page.
The URL says what it is: fantasyjoes.gg/draft/2026/compare/jonathan-taylor-vs-christian-mccaffrey. Year, then the two names. Whichever order you type them, you land on the same page.
The card that shows up when you share it
When one of these pages gets shared — in a group chat, on Reddit, wherever people argue about drafts — the preview image matters more than the page title, because the image is what shows up in the feed. So I made it worth seeing.
Every player in the game has a comic-style caricature I generate for them. The share card puts both players’ caricatures side by side, adds their position, team, and draft rank, drops a “VS” in the middle, and draws the live crowd-split bar right on the image. It’s built per matchup, from the same live data as the page, so the card for a real matchup shows the real split and the real art. It looks like a fight card, which is the point.

That card also broke on every single page for a while, which brings me to the parts that were harder than the idea.
The wrong Jefferson
There are two players named Jefferson in the NFL, and there was a college linebacker named Jefferson showing up in the commentary feed I was pulling from. My system for attaching expert takes to players checked whether the name it got back existed on a roster — which “Jefferson” does — but not whether the quote was about that Jefferson. So a page about Justin Jefferson, the star receiver, could show a take that was about someone else entirely.
That’s the kind of bug that makes the whole thing untrustworthy without ever throwing an error. If one page is confidently wrong, why would you believe the other 144? The fix wasn’t clever: before any take renders, a check reads the quote text and confirms it names the player the page is about. If it doesn’t, the take doesn’t show. No extra AI call, just a plain filter, applied to everything already published and everything new.
The share card was a different kind of failure — it crashed on every pair with an unhelpful error, so the fight card I’d built showed up as nothing. The rendering tool I used has a strict rule about how you lay out the image that isn’t caught when the code compiles, only when it runs. I rebuilt the card to follow the rule and wrapped every image and font it fetches in a timeout, so a slow request can’t take the whole card down again.
Making them fast
One more thing that wasn’t the idea but mattered: these pages are 100% public, but they were being run through the same login check as the rest of the site, which forced every request to be handled fresh instead of cached. For a page a search crawler hits, that’s slow for no reason. I pulled the compare pages out of that check and told the CDN it can hold each one at the edge for a day, and serve a slightly stale copy for up to a week while it refreshes. Now a crawler mostly hits a cached copy sitting close to it, and the page loads immediately.
Where this stands
The pages are live, they’re fast, and the data behind them is real. The fight I’m in now is a plain one: Google hasn’t indexed the site yet. A page that’s perfect and invisible does nothing, so getting these into the index — verifying the site in Search Console, submitting the sitemap, earning a few links pointing in — is the next problem, and it’s the one that decides whether any of this was worth building.
The part worth stealing, if you’re building something else: the thing your product already does may be generating the exact content people are searching for. My game’s whole job is answering “this player or that one,” and every one of those answers is a data point about a matchup someone will eventually search. Turning that into pages didn’t take new data or new writing — I just had to notice that the data exhaust was the SEO surface. Yours might be too.